

445

目次
こんにちは、美容室経営研究所Refineの井上です。
今回は、「美容室の経営にクラスタリングの手法を適用してみよう」ということで、簡単な例で分析してみようと思います。
はじめに
今回は、顧客の持つ情報から、3つのグループを作成する分析を行おうと思います。
グループに分けることで、グループ別のとるべきアプローチが見えてくるかもしれません。
分析には、教師無し学習であるk-means法を使用します。
k-means法は上記のようにあらかじめ目指すクラスタの数を決めて実行する必要があります。
データ定義
まずは今回使用するデータを見ていきましょう。
コードを見てもらえばわかる通り、乱数から生成しています。
import numpy as np
import pandas as pd
# データ生成
np.random.seed(42)
n_customers = 200
# 顧客データ: 年齢、来店頻度(年)、平均支出額
customer_ids = np.arange(1, n_customers + 1) # 顧客ID
ages = np.random.normal(35, 10, n_customers).astype(int)
visit_freqs = np.random.poisson(5, n_customers) # 年間来店回数
spendings = np.random.normal(12500, 2500, n_customers) # 平均支出額
data = pd.DataFrame({
'Customer ID': customer_ids,
'Age': ages,
'Visit Frequency': visit_freqs,
'Average Spending': spendings
})
data- Customer_ID:顧客ID
- Age:年齢
- Visit Frequency:来店頻度(=年間来店回数と仮定)
- Average Spending:平均支出額
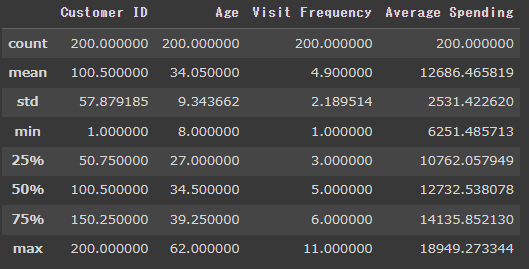
要約統計量も表示します
data.describe()顧客200名のデータを想定しています。
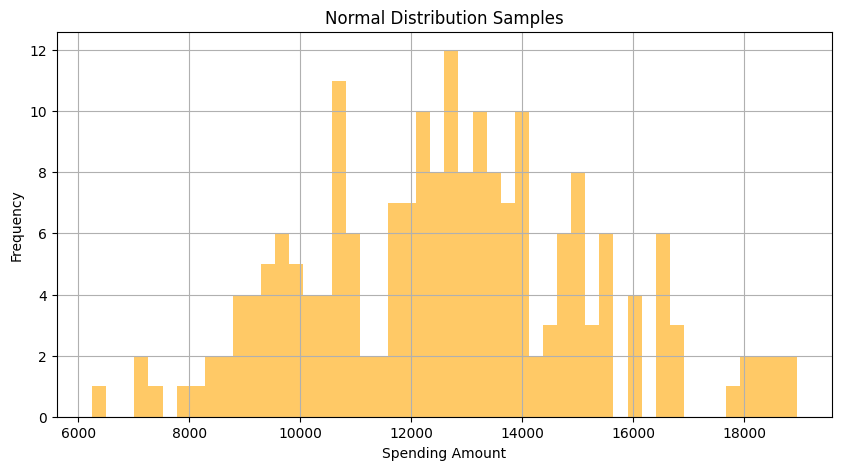
平均単価をプロットしてみます。
import matplotlib.pyplot as plt
import seaborn as sns
# ヒストグラムで結果を可視化
plt.figure(figsize=(10, 5))
plt.hist(data['Average Spending'], bins=50, color='orange', alpha=0.6)
plt.title('Normal Distribution Samples')
plt.xlabel('Spending Amount')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()平均単価は正規分布からの抽出です。