

目次
この投稿は、私の目指すマーケティングのあり方に近い考え方であり、好きな1冊でもある「ビッグデータ時代のマーケティングーベイジアンモデリングの活用ー」について、内容をまとめるとともにpythonコードでできるところは再現したい、という試みの記録です。
数回に分けて書いていこうと思います。
まず初めに書籍についての情報です。
<書籍情報>

- (著者)佐藤忠彦、樋口知之
- (発売)2013年1月22日
- (本の長さ)209ページ
- (出版社)講談社
書籍全体の内容としては、最終的に「階層ベイズモデル」や「状態空間モデル」をマーケティングに活かすことを目標として、段階的に説明が進んでいきます。
第1章ではマーケティングの概要、統計モデルがどのように活用されるのか、などについて、その先の章で線形回帰モデルをはじめとした統計モデルの説明から、ベイジアンモデリングへと話が展開していき、それらをマーケティングにおいてどのように活用していくかが記載されています。
この書籍を読む上での目的としては、マイクロマーケティング的観点でビッグデータがどう活用されるか、ベイジアンモデリングや状態空間モデルのポイント、を学ぶことにあると思います。
全体で一貫して小売業のマイクロマーケティングを想定して話が進んでいきます。
第1章 マーケティングの今:ビッグデータと統計モデリング
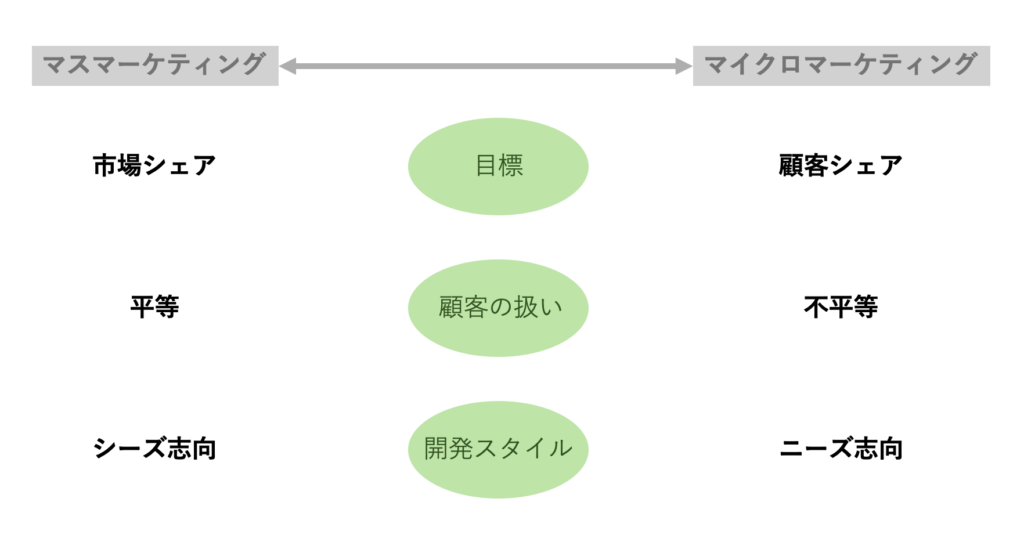
マイクロマーケティング
「マーケティング」という言葉が出始めた1980年代ごろには、市場の状況は右肩上がりで景気が良く、
企業は需要サイドの個別ニーズに注意を払わなくとも、平均ニーズを狙えばある程度の売り上げは確保できていました。
つまり消費者サイドで考えれば、当時の消費者はあまり多くの選択肢に触れることもなく、売られているものは良いものだと考えており、ある意味受動的とも言える購買が行われていました。
そんな時代における企業のマーケティングの目標は「市場シェアの拡大」にあります。
一方で、現代のマーケティングでは消費者は簡単に情報を取得、比較でき、多種多様な選択肢を与えられており、モノも溢れています。
企業ではそのような状況を加味して、「個別ニーズを把握したマイクロマーケティング」を行う必要性が増していると言えるでしょう。
近年、個人情報保護に関する規制等が厳しくなってきており詳細な個人に属する情報を取りにくいという状況から、マイクロマーケティングの限界が説かれることもありますが、私個人としては現在もある範囲に限定されたデータの取得は可能であり、得られる範囲で最大限データを活用してマイクロマーケティングに活かす、ということは、今後の方向性としてありなのかなと感じています。
そして、日本の企業のほとんどは中小企業であり、お店で言えば個人店など、小規模の店舗を運営する企業が多く、そのような企業の経営においてOne to Oneマーケティングをはじめとしたマイクロマーケティング手法のような個別性を加味したアプローチは重要な役割を果たしてくれると考えています。
個人にアプローチする方法についても連絡網を獲得したり、法に抵触しないよう注意を払いながら行う必要はあると思いますが、それでマイクロマーケティングが全く役に立たないということにはならないと考えます。
話が脱線してしまいましたが、
そのような企業のマイクロマーケティング活動における目標には、従来の「市場シェア」でなく、以下の「顧客シェア」そして「顧客ロイヤルティ」が使用されます。
・顧客シェア・・・消費者一人一人が購入した、ある商品カテゴリにおける、自社製品の割合
・顧客ロイヤルティ・・・自社ブランドに対する忠誠度(ある期間中の購買における、自社商品が購入された回数)
近年、IT技術の発展等により、代表的な2次データであるPOSデータは入手しやすくなりました。
マーケティングにおいて、1次データと2次データでは前者の方が重要視されることが多いですが、これは世間的に原因→結果の「仮説検証型アプローチ」が重要視されていることに起因しています。
2次データについては、結果→原因の「仮説発見型アプローチ」を行うために用いられることが多いです。
そのため、この結果から原因を推論するアプローチには2次データによるベイズ的手法が有効であると考えられますね。
小売業でのOne to Oneマーケティング
小売業で得られる2次データの種類はざっくりと以下のように分類できます。
・POSデータ:どの商品がいつ何個売れたか
・IDつきPOSデータ:上記のPOSデータにIDがついて誰が買ったかわかるようになったもの
・Webログデータ:Webサイトの閲覧履歴等
前述したように、One to Oneマーケティング等のマイクロマーケティング活動においては、大局的な観点だけでない異質性を考慮する必要があります。
異質性には、消費者異質性、時間的異質性の2つがあり、それぞれ下記のような意味合いの概念です。
1、消費者異質性
消費者一人一人の特性の違い。小売業で言えば消費者の購買要因であったり、年齢性別などをはじめとした特徴の違いを指す。
2,時間的異質性
同一の消費者にフォーカスした時に、例えば上記の購買要因が時間で変化している場合が多々見受けられる。そのような時間変化を時間的異質性という。
最近ではもうビッグデータという言葉は一般的になってきていますが、つい「ビッグデータから得られた観測変数から、消費者の行動は解明できる」という期待が独り歩きしてしまいがちです。
しかし、実際得られたデータによって消費者の行動がすべてわかるなどということは不可能であり、データに加え、消費者行動理論や経験等の様々な情報を用いて消費者理解を行う必要があります。
潜在変数
では、どのようなものが消費者の観測できない潜在的変数であるでしょうか?
この書籍の小売業での特定の商品を考えた場合、それは「家庭内在庫」、「ブランドロイヤルティ」、「参照価格」などが行動に影響する潜在変数と言えます。
そのようなマーケティングにおける潜在変数の推定などに統計モデルが活用されることがありますが、統計モデルには以下の機能があります。
- 個人ごとのパラメータをモデルに取り込み推定できる
- 時点ごとのパラメータをモデルに取り込み推定できる
- 潜在変数をモデルに取り込みその影響を評価できる
種類によっては、データは大規模でもある特定商品の購買データやプロモーションへの反応回数は非常に少ないことがあります。
つまり、マーケティングでの実際の課題解決のための解析においては、全体として大規模なデータでも特定の状況のためのデータは足りていない、という事態も発生するのです。
この問題について従来の統計的手法で解決するのは難しく、少数例と大量データの融合を行う手法が必要であります。
そしてそのような状況に対応可能なのがベイジアンモデリングです。
ベイジアンモデリングを用いることで、「個」に関する情報の集積体としてのビッグデータを活用し、不足する情報を推論することが可能となります。
帰納と演繹
マーケティングにおいては演繹推論の立場での解析、つまり仮説を立ててそれをデータを用いて検証するというアプローチが非常に多く行われています。
一方で、先ほど説明したように統計科学の諸手法を用いてデータから帰納的にマーケティング現象をモデル化するアプローチも存在します。この手法は、現象を支配している関係式などを観察データから推論していく、いわばデータ駆動型アプローチと呼ぶことができるでしょう。
ここで念のため、マーケティングにおける演繹推論と帰納推論の違いについて確認しておきます。
演繹推論:
4Pなど、マーケティングの定性的な一般理論に基づいて仮説を立て、その仮説をデータで検証する方法。
これは、マーケティング分野で伝統的に多く用いられるアプローチといえる。
帰納推論:
観測データから関係式や経験則を見つけ出し、そこから理論やモデルを構築する方法。
データからのパターン認識に基づくアプローチです。
これらのアプローチにはそれぞれ批判や対立が存在する場合があります。
具体的には、演繹推論の立場からは、帰納推論による研究は「マーケティング理論や消費者行動理論にのっとっていない」と批判されることがあります。
また逆に帰納推論の立場からは、演繹推論による研究は「データの裏づけが少なく、証拠が重要ではないか」と指摘されることがあります。
(この本では、マーケティングにおいてベイジアンモデリングの役割を明確にするため、どちらが正しいかではなく両アプローチの仕組みや特徴を理解することが重要であると述べています。)
