目次
こんにちは、美容室経営研究所Refineの井上です。
今回は、ポアソン回帰モデルを使ってみようということで、「一定期間行ったキャンペーンが顧客の来店頻度にどのような効果をもたらしたか」、という分析をポアソン回帰モデルを用いて行っていこうと思います。
1.はじめに
今回想定している状況は、クーポンなどのキャンペーンのお知らせを出した顧客と出さなかった顧客について、出したことが顧客の来店を促したかどうか知りたいときの分析です。
このような効果測定を行う場合は、全員にお知らせを出してしまうと違いがわからなくなってしまうので、ランダムに出すグループと出さないグループを作成して、キャンペーンが寄与しているか考えることになります。
もし全員に出してしまっている場合は、予測(もし出していたら)のようなものを用いて分析を行うことになりますが、確度は下がります。
データの定義
使用するデータは、
- 顧客の来店回数(目的変数)
- キャンペーン有無(0or1のバイナリ)
- 顧客の年齢
- 顧客の性別
です。
データ生成
以下のコードからダミーデータを生成していきます。(今回はベタ打ちしています)
import pandas as pd
import numpy as np
import pymc as pm
# ダミーデータの作成
data = {
'campaign': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'age': [25, 35, 36, 20, 21, 23, 43, 32, 25, 22, 18, 45, 55, 65, 42, 32, 33, 31, 30, 28, 24, 54],
'gender': [0, 1, 0, 1, 0, 0, 0, 0, 0, 0 ,1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1],
'visits': [3, 2, 4, 1, 2, 3, 3, 1, 3, 2, 4, 5, 4, 3, 4, 6, 8, 8, 6, 4, 6, 6]
}
df = pd.DataFrame(data)
df
各列は、キャンペーン有無、年齢、性別、期間来店回数を表しています。
もちろん実務では、これだといろいろと不十分なデータでしょう…
要約統計量も表示してみます。
df.describe()
データは22件で少ない気もしますが、今回はこのまま続行します。
2.モデル説明
一般化線形モデル
今回のモデルは、一般化線形モデル(GLM:Generalized linear model)と呼ばれるモデルの一種で、ポアソン分布を使用した、ポアソン回帰モデルです。
一般化線形モデルは目的データに対して指数型分布を仮定してモデリングを行います。
簡単に言ってしまえば、線形回帰の応用版(柔軟にしたもの)と言えるでしょう。
ポアソン分布とポアソン回帰モデル
ポアソン回帰モデルは以下のようになります。
$$y_i \sim \text{Poisson}(\lambda_i)$$
$$\text{where} \quad \text{gender}_i = \begin{cases} 0 & \text{if male} \\ 1 & \text{if female} \end{cases}$$
ポアソン回帰モデルでは、ある期間内にイベントが発生する回数\((y)\) がポアソン分布に従うと仮定します。
また、ポアソン分布はカウントを表す分布であり、\((\lambda > 0)\) である必要があるため、上記のように回帰式が指数変換されています。
説明変数と回帰係数から成る部分は線形予測子と呼ばれ、対数リンク関数を用いて以下のように表現されます。
したがって、先ほどの式は、逆リンク関数によって \((\lambda)\)を表現していたということになります。
$$
\lambda = \exp(X\beta)
$$
このモデルを用いることで、説明変数 (X) の異なる値に対するイベント発生の平均回数 \((\lambda) \)を予測することができます。
ポアソン分布の確率質量関数(PMF)は以下の式で表されます。
$$
P(Y=y|\lambda) = \frac{e^{-\lambda}\lambda^y}{y!}
$$
そして、この分布の尤度関数が
$$L(\lambda|y) = \prod_{i=1}^{n} \frac{e^{-\lambda} \lambda^{y_i}}{y_i!}$$
です。
これを対数変換して、対数尤度とした以下の式を用いて最尤推定を行います。
$$\log L(\lambda|y) = \sum_{i=1}^{n} \left( -\lambda + y_i \log(\lambda) – \log(y_i!) \right)$$
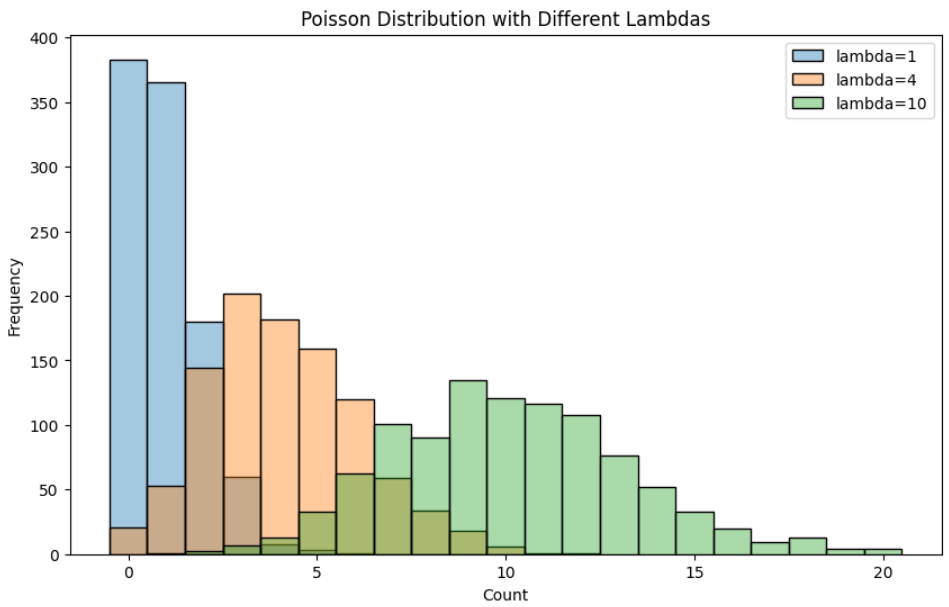
以下に、\(\lambda\)の値を変えた、ポアソン分布を図示してみます。
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# パラメータの異なるポアソン分布からサンプルデータを生成
lambdas = [1, 4, 10]
data = {f"lambda={l}": np.random.poisson(lam=l, size=1000) for l in lambdas}
# ヒストグラムで表示
plt.figure(figsize=(10, 6))
for label, values in data.items():
sns.histplot(values, kde=False, label=label, alpha=0.4, discrete=True)
plt.title('Poisson Distribution with Different Lambdas')
plt.xlabel('Count')
plt.ylabel('Frequency')
plt.legend()
plt.show()