

目次
美容室経営研究所Refineの井上です。
今回は、ある美容室の売上高を時系列モデルであるホルト・ウィンターズ法(Holt-Winters method)を用いて分析していこうと思います。
データは私が自作したものです!
データの読み込みと説明
読み込み
まずはデータセットを読み込んでいこうと思います。
今回は、statsmodelsのtsa(時系列分析)から、holtwintersのExponentialSmoothingを使用しますので先にインポートしておきます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from statsmodels.tsa.holtwinters import ExponentialSmoothing
#読み込み
data = pd.read_excel('revenue24.xlsx')
data.head()
今回のデータは上記のようにいたってシンプルです。
美容室の月間売上高が24カ月分入っています。
通常であれば、美容室のようなビジネスの売上高を予測する際には、以前紹介した重回帰分析など、説明変数を用いるモデルを使用した方がいいと思いますが、今回は売上高の時系列データのみで「ホルト・ウィンターズモデル」を用いて分析を行ってみ追うと思います。
仮説を立ててみる
売上高のデータのみで、しかも24カ月分だけとなると、あまりいいモデルはできないかもしれません(^▽^;)
12カ月周期で周期性を把握したくても、2回転分しかデータがありませんので、データセットをトレーニングとテストに分けてやるとうまくいかなそうです。
そのため今回は全部のデータでモデリングすることにします。
EDA(Explanatory Data Analysis)
データの様子を見ていこうと思います。
# 日付をインデックスに設定
data['月'] = pd.to_datetime(data['月'])
data.set_index('月', inplace=True)
# データのプロット
plt.figure(figsize=(12, 6))
plt.plot(data['売上'], label='Monthly Revenue')
plt.title('Monthly Revenue Data')
plt.xlabel('Month')
plt.ylabel('Revenue')
plt.legend()
plt.show()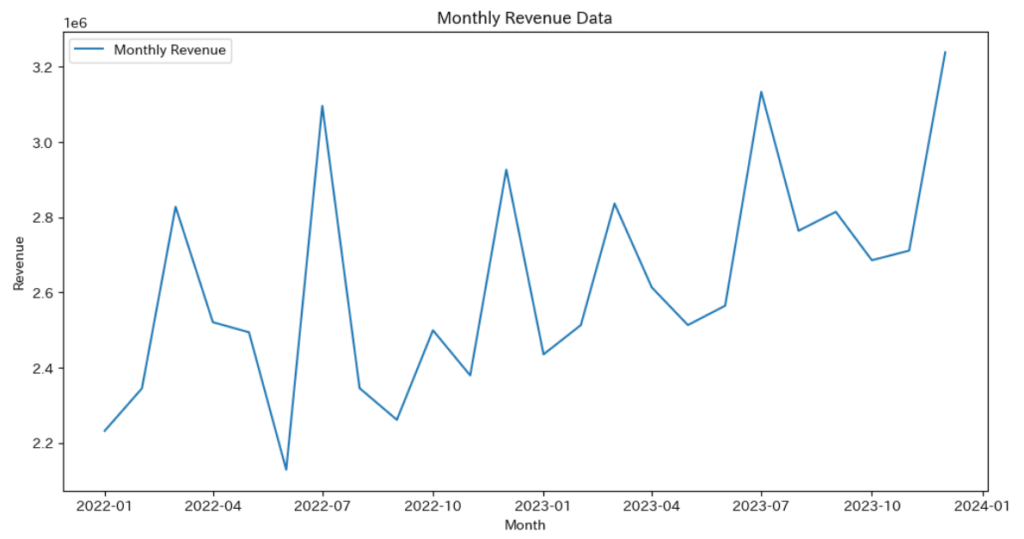
どうでしょうか?
緩やかな上昇トレンドと、周期性が見られますね。
周期は美容業界でよく繁忙月と言われる7月、12月、3月になるようにデータを作成しました。
この周期性をとらえた分析ができればいいなと思います。
モデリング
ホルト・ウィンターズ分析について
ホルトウィンタース法は、季節性を含む時間系列データの予測に使われる統計的予測手法です。
この方法は、レベル(平均値)、トレンド(傾向)、季節性の3つの成分を使って将来の値を予測します。
具体的には、以下のような特徴を持っています
- レベルの調整::データの平均値に近い水準を保つ。
- トレンドの調整: データの増加や減少の傾向を捉える。
- 季節性の調整::年間、月間、週間などの周期的なパターンを考慮。
この方法は、時間の経過とともに変化するデータのパターンを捉え、それを使って未来の値を予測するのに適しています。
数式を用いて表現すると以下のようになります。
加法的ホルト・ウィンターズ法
今回使用している加法的ホルト・ウィンターズ法の更新式は以下の通りです
予測値の計算:
$$\hat{y}_{t+h|t} = \ell_t + hb_t + s_{t+h-m(k+1)}$$
ただし、
・\(\hat{y}_{t+h|t}\) は時刻\(t\)における\(t+h\)の予測値
・\(\ell_t\)は\(t\)におけるレベル成分
・\(b_t\)はトレンド成分。
・\(s_{t+h-m(k+1)}\) は季節成分
・\(m\)は季節周期
・\(k\)は\((t+h-1)\)を\(m\)で割った商
レベル成分の更新:
$$\ell_t = \alpha (y_t – s_{t-m}) + (1 – \alpha)(\ell_{t-1} + b_{t-1})$$
ただし、
・\(y_t\)は時刻\(t\)の観測値
・\(\alpha\)はレベルに関する平滑化パラメータ
トレンド成分の更新:
$$b_t = \beta^* (\ell_t – \ell_{t-1}) + (1 – \beta^*) b_{t-1}$$
ただし、
・\(\beta^*\)は、トレンドに関する平滑化パラメータ
季節成分の更新:
$$s_t = \gamma (y_t – \ell_{t-1} – b_{t-1}) + (1 – \gamma) s_{t-m}$$
ただし、
・\(\gamma\)は、季節成分に関する平滑化パラメータ
モデル1学習
モデルの学習に入ります。
とりあえず、12カ月周期の季節変数を入れて分析します。
# すべてのデータをトレーニングに使用(季節成分)
model_full_data = ExponentialSmoothing(data['売上'],
seasonal='add',
seasonal_periods=12).fit()完了したのでプロットしてみましょう。
(最適化が収束せず終了したと警告が出ましたが、データも少ないので仕方ないのかなと思います。とりあえずそのまま進めます(^▽^;))
# モデルのフィット結果のプロット
fitted_values = model_full_data.fittedvalues
plt.figure(figsize=(12, 6))
plt.plot(data['売上'], label='Actual Revenue')
plt.plot(fitted_values, label='Fitted Values', linestyle='--')
plt.title('Holt-Winters Model Fitting on Full Data')
plt.xlabel('Month')
plt.ylabel('Revenue')
plt.legend()
plt.show()
# モデルのパラメータを表示
model_full_data.params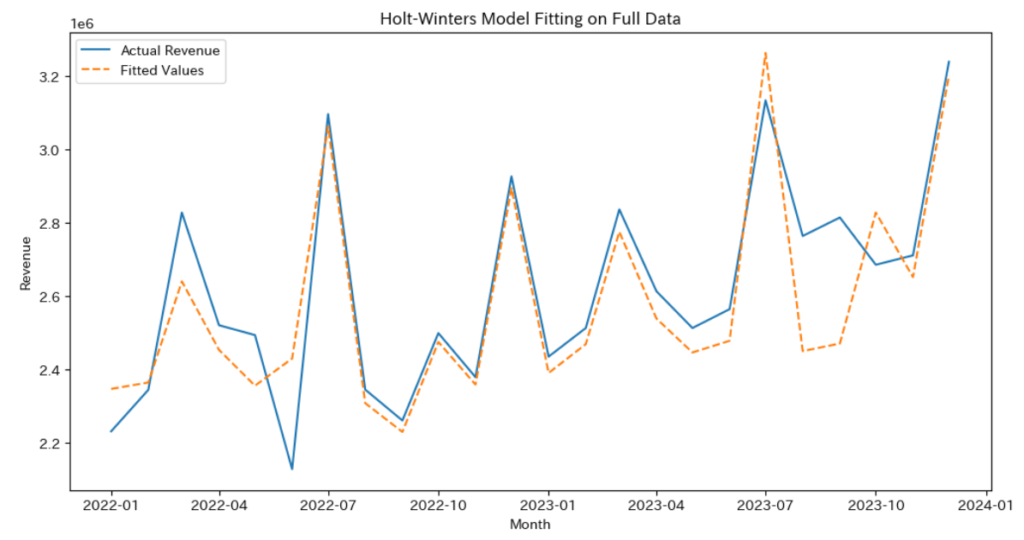
次に得られたパラメータを表示します。
# モデルのパラメータを表示
model_full_data.params
ちょっとごちゃついてて見にくい感じなのでDataFrame型に変換しましょう。
#パラメータをデータフレームに
params = model_full_data.params
params_df = pd.DataFrame(list(params.items()), columns=['Parameter', 'Value'])
params_df = params_df[params_df['Parameter'] != 'initial_seasons']
params_df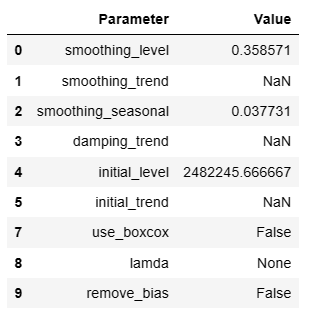
スッキリしました♪
各項目について説明します。
smoothing_level:データのレベルをどの程度平滑化するかを制御するパラメータ。0と1の間の値で、ここでは約0.36と推定されており、モデルが新しい観測値に適度に反応することを示している。smoothing_trend: トレンド成分の平滑化に関するパラメータ。(使用していません)smoothing_seasonal: 季節性成分をどの程度平滑化するかを制御するパラメータ。この値が小さいことは、季節成分がデータに対して比較的小さな調整を加えることを示唆。damping_trend: トレンドが時間とともに減衰する度合いを制御するパラメータ。(使用していません)initial_level: 時系列の初期レベル(スタート地点)の推定値。initial_trend: 初期トレンドの推定。initial_seasons:季節性成分の初期値の配列。これは時系列データの最初の季節周期に対する補正値を示しており、季節性の強さとパターンを示している。
# initial_seasons のデータフレーム
initial_seasons_df = pd.DataFrame(params['initial_seasons'], columns=['Initial Season Value'])
initial_seasons_df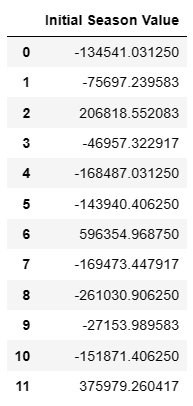
「Initial Season Value」は、時系列分析における季節性指数平滑化モデルの初期季節成分を指します。
ちなみにこれらの各パラメータがどのように求められているかですが、ホルト・ウィンターズ法でのパラメータの最適化には、一般的に最小二乗法や尤度に基づく方法が使用されているらしいです。
その最適化についてchatGPTに聞いてみました↓
Pythonの
statsmodelsライブラリを使用してホルト・ウィンターズモデルをフィットする場合、内部的には次のアルゴリズムが使われることが多いです:
- L-BFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno):
- 限定メモリを持つ準ニュートン法の一種で、特にパラメータの数が多い問題に適しています。
- statsmodelsではデフォルトで使用されることがあります。
- Nelder-Mead シンプレックスアルゴリズム:
- 勾配情報を必要としない直接探索法で、比較的単純な問題に適しています。
- Powell の方法:
- 勾配を使わない最適化手法で、一次元探索を繰り返すことで多次元の最適化問題を解決します。
- TNC(Truncated Newton Conjugate-Gradient):
- 制約付き問題に対するニュートン法の一種で、大規模な問題に適しています。
最適化アルゴリズムの選択は、実装されているライブラリや、特定のデータやモデルの問題に最適なものを選ぶことに依存します。
statsmodelsでは、fitメソッドのoptimizationパラメータを通じて、使用する最適化アルゴリズムを選択することができます。デフォルトでは、多くの場合L-BFGSが使われることが多いですが、ユーザーはfitメソッドの引数に応じて他の最適化アルゴリズムを指定することも可能です。
とのことです。なるほど...
次に各周期成分に分けてプロットしてみようと思います。
# モデルの成分を抽出
fitted_values = model_full_data.fittedvalues
level = model_full_data.level
seasonal = model_full_data.season
resid = model_full_data.resid
# 各成分のプロット
plt.figure(figsize=(14, 10))
plt.subplot(411)
plt.plot(fitted_values, label='Fitted Values')
plt.title('Fitted Values')
plt.legend()
plt.subplot(412)
plt.plot(level, label='Level')
plt.title('Level Component')
plt.legend()
plt.subplot(413)
plt.plot(seasonal, label='Seasonal')
plt.title('Seasonal Component')
plt.legend()
plt.subplot(414)
plt.plot(resid, label='Residual')
plt.title('Residual Component')
plt.legend()
plt.tight_layout()
plt.show()

残差が大きいところがありますが、季節成分はそこそことらえることができているかなと思います。
モデル1予測
次に作成したモデル1でこれより先の12カ月分の予測をしてみます。
# 次の12ヶ月の売上を予測
forecast_next_12 = model_full_data.forecast(12)
# 予測結果のプロット
plt.figure(figsize=(12, 6))
plt.plot(data['売上'], label='Actual Revenue')
plt.plot(forecast_next_12, label='Forecasted Revenue', linestyle='--')
plt.title('12-Month Revenue Forecast')
plt.xlabel('Month')
plt.ylabel('Revenue')
plt.legend()
plt.show()
forecast_next_12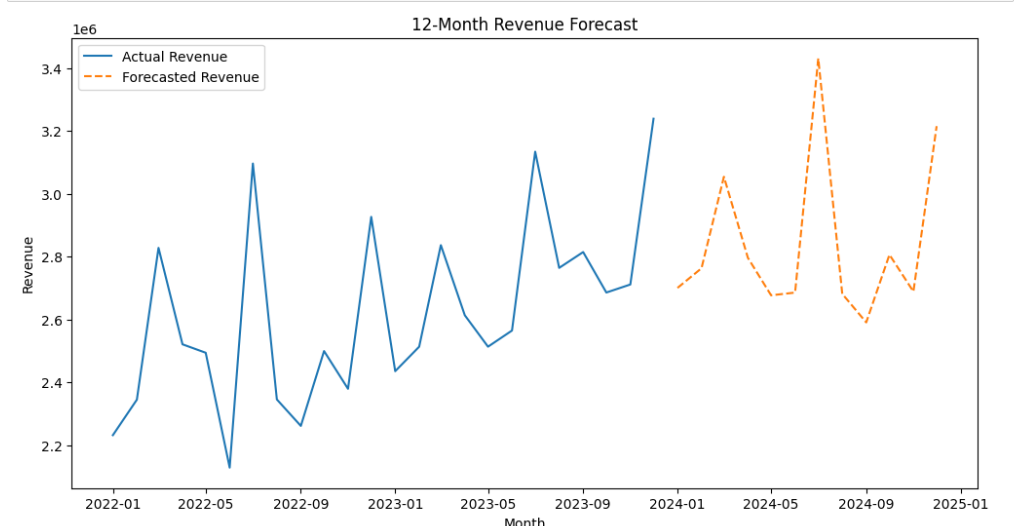

個人的にはまあまあではないかと思います。
ただ、トレンドを含めていないので売り上げは上昇していないですね。
次はトレンドを含めてみようと思います。