

目次
モデリング
モデル1(Logistic Regression)
では、説明変数と目的変数を設定してモデリングしましょう。
# 修正後のデータセットを用いてロジスティック回帰モデルを構築
X = data[['性別', '年代', '平均来店周期(日)', '来店回数']]
y = data['新メニュー']statsmodelsのロジスティック回帰を実行します。
モデル式は、リンク関数にロジットを用いて以下のように表現されます。
\begin{equation}
\log\left(\frac{P(Y=1)}{1 – P(Y=1)}\right) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \beta_4 x_4
\end{equation}
これをY=1についての確率とすると以下のように変形できます。
\begin{equation}
P(Y=1) = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \beta_4 x_4)}}
\end{equation}
import statsmodels.api as sm
# 定数項を追加
X_sm = sm.add_constant(X)
# ロジスティック回帰モデルを構築
model_rogi = sm.Logit(y, X_sm)
result_rogi = model_rogi.fit()
# 結果の要約を表示
result_rogi.summary()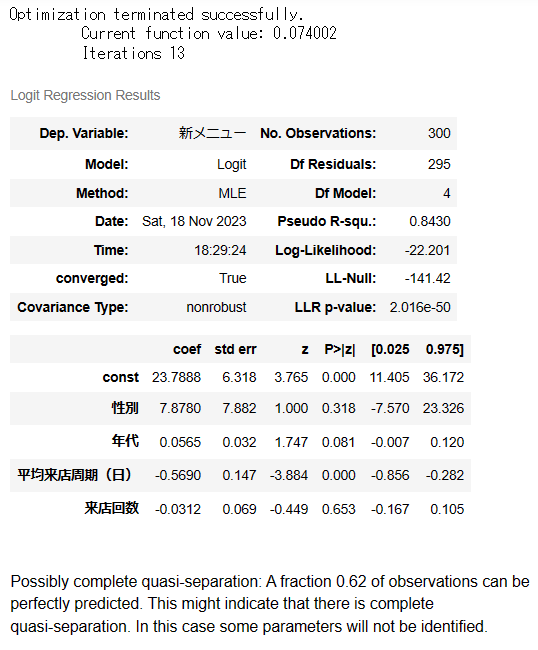
説明力は、まあまあなモデルになりました。
年代や平均来店周期などが活用できそうですね。
有意でない変数もありますが、とりあえずこのままのデータセットで分析を先に進めていきます。
モデル2(Random Forest)
先ほどは、ロジスティック回帰モデルで実装しましたが、今度はランダムフォレストモデルを使用して、精度が向上するか見てみようと思います。
sklearnのRandomForestClassifierを使用します。
import pandas as pd
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# データを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# ランダムフォレストモデルの構築
rf_model = RandomForestClassifier(random_state=0)
rf_model.fit(X_train, y_train)
# テストセットでの予測と混同行列の計算
y_pred = rf_model.predict(X_test)
conf_mat = confusion_matrix(y_test, y_pred)
# 混同行列をDataFrameに変換
conf_mat_df = pd.DataFrame(conf_mat,
index=['実際: 0', '実際: 1'],
columns=['予測: 0', '予測: 1'])
conf_mat_df
混同行列を出力してみました。
なかなかよさそうですね!
お次は分類レポートを出力してみましょう。
# 分類レポートの計算
class_report = classification_report(y_test, y_pred, output_dict=True)
# 分類レポートをDataFrameに変換
class_report_df = pd.DataFrame(class_report).transpose()
class_report_df
一応各出力について説明します。
- Precision(適合率):クラス1の適合率は約87.50%です。これは、モデルがクラス1と予測したデータポイントのうち、約87.50%が実際にクラス1であったことを意味します。
- Recall(再現率):クラス1の再現率は約93.33%で、これは実際のクラス1のデータポイントのうち約93.33%がモデルによって正しく識別されたことを示します。
- F1-Score(F1スコア):クラス1のF1スコアは約90.32%で、これは適合率と再現率の調和平均で、クラス1に対するモデルの精度が高いことを示します。
- Support(サポート):クラス1のサポートは15とあり、テストデータセット内のクラス1の実際のインスタンス数が75であることを意味します。
- Accuracy(正確度):全体の正確度は約96.67%で、モデルが全てのクラスの予測に対してこの割合で正しい予測を行ったことを示します。
- Macro Avg(マクロ平均):マクロ平均はクラス間での平均を取る際にクラスのサンプルサイズを考慮しないため、クラスの不均衡を考慮しない平均値です。
- Weighted Avg(加重平均):加重平均はクラスのサンプルサイズを考慮して計算されます。
モデル選択
モデル1のロジスティック回帰とモデル2のランダムフォレストは、どちらを用いるのがよさそうか交差検証を用いて比較してみます。
ちなみに、ここではロジスティック回帰を改めてsklearnにてモデリングしています。
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
#モデルのインスタンス化
logistic_model = LogisticRegression()
random_forest_model = RandomForestClassifier(random_state=0)
#5分割交差検証
cv = KFold(n_splits=5, random_state=0, shuffle=True)
#正解率を格納
logistic_cv_scores = cross_val_score(logistic_model, X, y, cv=cv, scoring='accuracy')
random_forest_cv_scores = cross_val_score(random_forest_model, X, y, cv=cv, scoring='accuracy')
#正解率の平均と標準偏差で比較
logistic_cv_mean = logistic_cv_scores.mean()
logistic_cv_std = logistic_cv_scores.std()
random_forest_cv_mean = random_forest_cv_scores.mean()
random_forest_cv_std = random_forest_cv_scores.std()
#データフレームにして表示
model_comparison_df = pd.DataFrame({
'Model': ['Logistic Regression', 'Random Forest'],
'Mean Accuracy': [logistic_cv_mean, random_forest_cv_mean],
'Standard Deviation': [logistic_cv_std, random_forest_cv_std]
})
model_comparison_df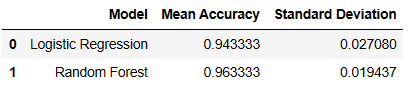
正解率で比較すると、ランダムフォレストの方が優れていそうですね。
それではこのモデルを用いて分析をしてみましょう。
モデルを活用する
上記で作成したモデルをしようして、Aさん【女性、35歳、60日平均、5回来店履歴】の顧客が新メニューをやりそうかやらなそうか、見てみましょう。
# Aさんというデータポイントを作成
person_A = pd.DataFrame({
'性別': [1], #女性
'年代': [35], #35歳
'平均来店周期(日)': [60], # 60日
'来店回数': [5] #5回
})
# このデータポイントで予測
predicted_probability = rf_model.predict_proba(person_A)[0]
prob_df = pd.DataFrame(predicted_probability, index=['新メニューを利用しない確率', '新メニューを利用する確率'], columns=['確率'])
prob_df
やらなそうですね(笑)
次に、新メニューをやる確率が50%以上なのに実際にはまだやっていない顧客を抽出してみます。
# テストデータに対して予測確率を計算(新メニューを試す確率)
test_probs = rf_model.predict_proba(X_test)[:, 1]
#テストデータを利用
test_data_with_probs = X_test.copy()
# 新メニューを行う確率と実際の新メニュー利用状況
test_data_with_probs['新メニューを試す確率'] = test_probs
test_data_with_probs['実際の新メニュー利用'] = y_test.values
#フィルターで対象を抽出
#確率が0.5以上で実際の利用が0
non_users_with_high_prob = test_data_with_probs[(test_data_with_probs['新メニューを試す確率'] >= 0.5) &
(test_data_with_probs['実際の新メニュー利用'] == 0)]
non_users_with_high_prob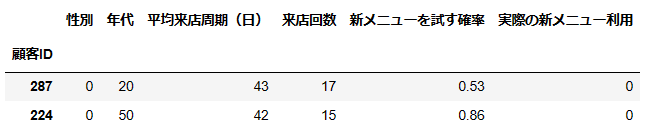
顧客IDが287と224の顧客は見込みがありそうなので、何か店舗でアプローチしてみるのがいいかもしれませんね!
次は、少し基準を下げて、新メニューをやる確率が30%以上50%未満で実際にはまだやっていない顧客を抽出してみます。
# テストデータに対して予測確率を計算(新メニューを試す確率)
test_probs = rf_model.predict_proba(X_test)[:, 1]
# 新メニューを試す確率と実際の新メニュー利用状況を含むデータフレームを作成
test_data_with_probs = X_test.copy()
test_data_with_probs['新メニューを試す確率'] = test_probs
test_data_with_probs['実際の新メニュー利用'] = y_test.values # 実際の利用状況を追加
#フィルターで対象を抽出
#確率が0.3以上0.5未満で実際の利用が0
non_users_with_high_prob = test_data_with_probs[(test_data_with_probs['新メニューを試す確率'] >= 0.3) &
(test_data_with_probs['新メニューを試す確率'] < 0.5) &
(test_data_with_probs['実際の新メニュー利用'] == 0)]
non_users_with_high_prob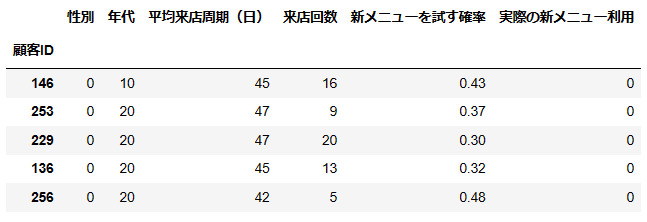
5名抽出できました。
上記の顧客も何かアプローチすれば新メニューを試してくれるかもしれません。
今回は、代表的な分類モデルである、ロジスティック回帰とランダムフォレストを使用してみました。
有意でない変数を取り除いて分析したり、検証しなければならないことは残っていますが、今回のような顧客の反応の属性を見るのに面白いモデルだと思います。
では♪
参考書籍
多変量解析入門――線形から非線形へ
小西 貞則 (著)
scikit-learn、Keras、TensorFlowによる実践機械学習 第2版
Aurélien Géron (著), 下田 倫大 (監修), 長尾 高弘 (翻訳)
データ解析のための統計モデリング入門 一般化線形モデル・階層ベイズモデル・MCMC (確率と情報の科学)
久保 拓弥 (著)