

目次
モデリング
モデル1
モデル1学習(scikit-learnバージョン)
ここでは、sikit-klearnを用いて重回帰モデルを構築していきます。
モデルは5つの説明変数xを用いて売上\(y\)をモデリングする、定数項ありの以下の式で表されます。
\begin{equation} y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \beta_4 x_4 + \beta_5 x_5\end{equation}
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
#データをトレーニングセットとテストセットに分ける
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# モデル学習
regressor = LinearRegression()
regressor.fit(X_train, y_train)
# 作成したモデルで予測
y_pred = regressor.predict(X_test)
#MSEと決定係数を計算
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 各係数をデータフレームに格納
coeff_df = pd.DataFrame(regressor.coef_, X.columns, columns=['Coefficient'])
coeff_df.loc['Intercept'] = regressor.intercept_
# 評価結果をデータフレームに格納
evaluation_df = pd.DataFrame({'Mean Squared Error': [mse], 'R-squared': [r2]})
evaluation_df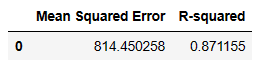
MSEと決定係数を表示しました。
そこそこな結果と言えましょうか…
モデル1結果解釈
次に各係数を見ていきます。
coeff_df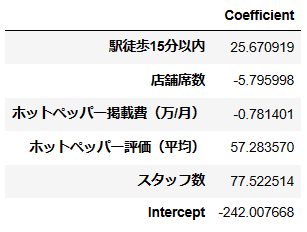
これを見ると、駅徒歩15分以内、ホットペッパー評価、スタッフ数の3つが売り上げに対してプラスに働いているようです。
では、これらの係数の重要度をソートして視覚的に確認してみましょう!
plotlyで図示してみます。
import plotly.express as px
#プロットしたい変数(定数項を除く)
coeff_plot_df = coeff_df.iloc[0:5]
# 係数を降順にソート
coeff_sort_df = coeff_plot_df.sort_values(by='Coefficient', ascending=False)
# 係数のプロット
fig = px.bar(coeff_sort_df, x=coeff_sort_df.index, y='Coefficient', title='係数の重要度')
fig.show()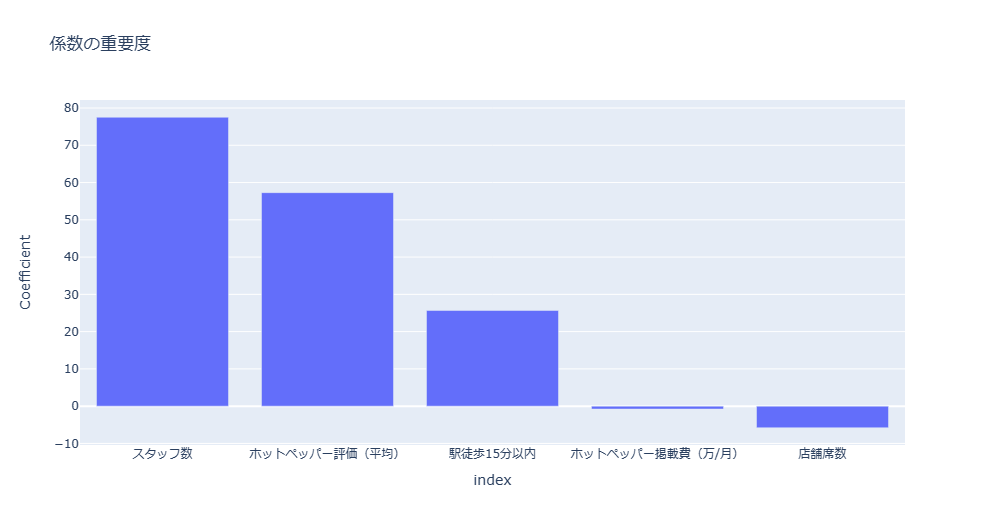
ホットペッパー掲載費はわかりませんが、席数がマイナスに働くことはないだろ。と突っ込みたくなる結果ですね(笑)
私のお手製データなので、このような結果も出ますのでお許しください(^▽^;)
以下では、statsmodelsを用いてsklearnでやったことと同じことをやっています。
モデル1学習(statsmodelsバージョン)
違いは、statsmodelsの方が統計モデルに特化しているのでサマリーで簡単にいろいろな情報を表示できることですね。
定数項を追加する操作があるので、そこだけ次元を間違えないよう注意が必要です。
import statsmodels.api as sm
#元のXに定数項を追加してsmに対応させる
X_sm = sm.add_constant(X)
#データをトレーニングセットとテストセットに分ける
X_train, X_test, y_train, y_test = train_test_split(X_sm, y, test_size=0.2, random_state=0)
# モデル学習
model = sm.OLS(y_train, X_train).fit()
# 作成したモデルで予測
y_pred = model.predict(X_test)
# 結果
model.summary()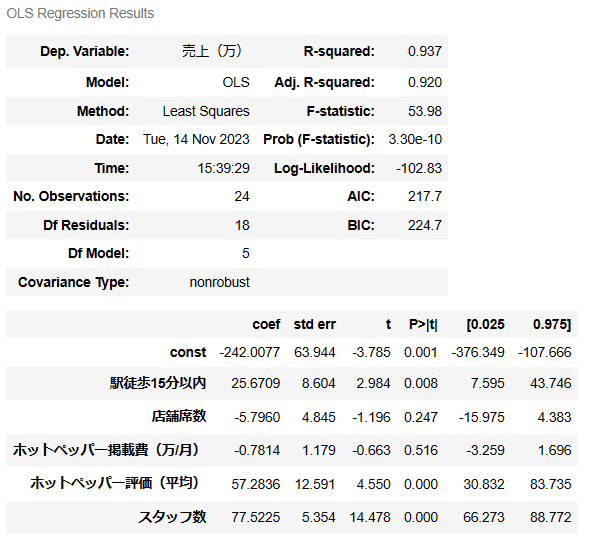
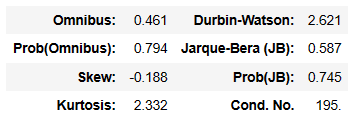
見比べればわかりますが、sklearnと係数などの扱いが異なるため、少し結果も異なります。
これだと決定係数も良い感じになっており、説明変数3つが有意な結果となっています。
モデル1で予測
では、この作成したmodelを使用して、「駅徒歩15分以内、4席、HPB7.7万円、HPB評価4.5、スタッフ4人」のお店を出店したとして、売上を予測してみましょう。
# 駅徒歩15分以内、4席、HPB7.7万円、HPB評価4.5、スタッフ4人の場合で予測してみる
new_data = np.array([1, 4, 7.7, 4.5, 4])
#切片と係数を取得
intercept, coefficients = model.params[0], model.params[1:]
# 新しいデータに定数項を追加
new_data_with_intercept = sm.add_constant(np.array([new_data]), has_constant='add')
# 新しいデータポイントでの予測値を計算
prediction = model.predict(new_data_with_intercept)
# 予測値を表示
print("予測値:", prediction)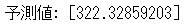
上記の条件の店舗であれば、約月322万の売り上げが見込めると出ました。
モデル2
モデル2学習
店舗席数の変数が、VIFが大きく、有意でもない結果が出ていましたね。
係数もマイナスで直観にも反するものでしたので、モデルから除外してみることにします。
# 説明変数から店舗席数を削除してみる
X_modified = df[['駅徒歩15分以内', 'ホットペッパー掲載費(万/月)', 'ホットペッパー評価(平均)', 'スタッフ数']]
X_modified.head()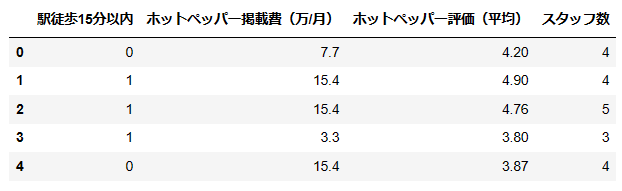
この4つの変数で学習させます。
同じようにVIFも計算してみましょう。
# 各特徴量のVIF
vif_data_modified = pd.DataFrame()
vif_data_modified["Feature"] = X_modified.columns
vif_data_modified["VIF"] = [variance_inflation_factor(X_modified.values, i) for i in range(X_modified.shape[1])]
vif_data_modified
さっきよりはまともになりましたね(笑)
とりあえずこのままmodel_modifiedを構築しようと思います。
先ほどと同じくstatsmodelsを使用します。
import statsmodels.api as sm
#元のXに定数項を追加してsmに対応させる
X_sm_modified = sm.add_constant(X_modified)
#データをトレーニングセットとテストセットに分ける
X_train_modified, X_test_modified, y_train, y_test = train_test_split(X_sm_modified, y, test_size=0.2, random_state=0)
# モデル学習
model_modified = sm.OLS(y_train, X_train_modified).fit()
# 作成したモデルで予測
y_pred_modified = model_modified.predict(X_test_modified)
# 結果
model_modified.summary()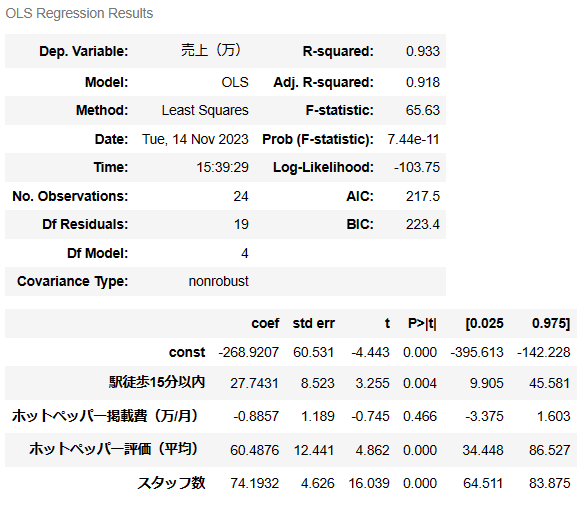
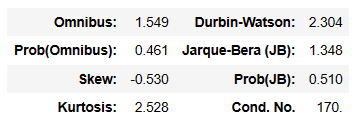
先ほどのモデルよりも全体的にいい感じな気がしますね。
モデル2で予測
では、この結果を用いて「駅徒歩15分以内、HPB7.7万、HPB評価4.5,、スタッフ4人」のお店の売上高を予測してみましょう。(各値は同じで、変数が一つ減らしただけです)
#15分以内、HPB7.7万、HPB評価4.5,、スタッフ4人の場合で予測してみる
new_data_modified = np.array([1, 7.7, 4.5, 4])
#切片と係数を取得
intercept_modified, coefficients_modified = model_modified.params[0], model_modified.params[1:]
# 新しいデータに定数項を追加
new_data_with_intercept_modified = sm.add_constant(np.array([new_data_modified]), has_constant='add')
# 新しいデータポイントでの予測値を計算
prediction_modified = model_modified.predict(new_data_with_intercept_modified)
# 予測値を表示
print("予測値:", prediction_modified)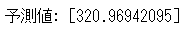
320万と出力されました。
さっきとほとんど同じですね。